The U.S. Department of Energy’s Office of Science has allocated 60% of the available time on the leadership-class supercomputers at DOE’s Argonne and Oak Ridge national laboratories to 81 computational science projects for 2025, including a project led by Drummond Fielding, assistant professor of astronomy in the College of Arts and Sciences.
Fielding’s project, “Pushing the Frontier of Cosmic Ray Transport in Interstellar Turbulence,” will be funded through DOE’s Innovative and Novel Computational Impact on Theory and Experiment (INCITE) program. His team has been allocated 600,00 “node-hours” on the Oak Ridge Leadership Computing Facility’s 2 exaflops peak Frontier, an HPE Cray EX supercomputer that debuted in May 2022 as the world’s fastest supercomputer. Each node has four GPUs, each with 220 cores (processing units), an impressive amount of computing power.
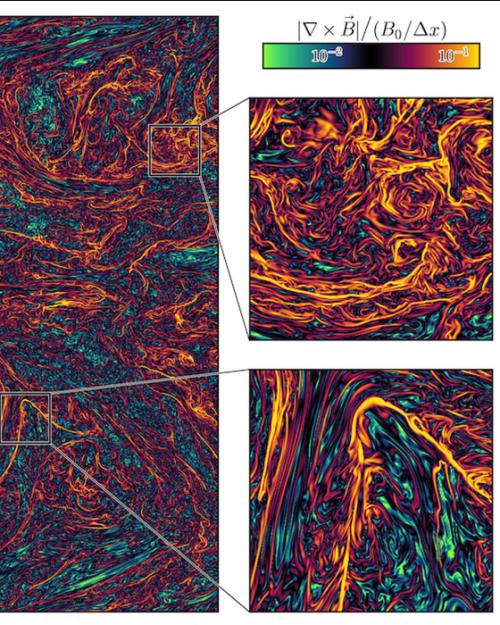
“We are going to run the largest simulations of the magnetized gas that pervades the space between stars, with the aim of understanding a crucial missing piece in our models for how stars and galaxies form,” Fielding said.
The source of cosmic ray scattering has been long debated, which limits our understanding of galaxy formation and black hole growth, according to Fielding. By running the largest simulations of magnetized turbulent astrophysical plasma to date, Fielding and his team will be able to study how the dissipation of plasma around galaxies shapes both magnetic and density structures. These structures are believed to play a central role in cosmic ray transport as well as the scattering of background radio sources, known as extreme scattering events.
“By studying both radio wave and cosmic ray transport in these groundbreaking realistic simulations, we will be able to leverage the full power of the exascale computers to solve several of the most pressing unsolved questions in modern astrophysics,” said Fielding.
Co-investigators on the project include Philipp Kempski, Eliot Quataert and Matthew Kunz, Princeton University; Philipp Grete, Hamburg Observatory; Alexander Philippov, University of Maryland, College Park; and James Stone, Institute for Advanced Study.
Fielding has also contributed to another large-scale computer project, this one involving artificial intelligence.
“There's been a lot of interest in how artificial intelligence can help us accelerate and improve how we solve for the equations of motion for liquids, gases, and plasmas. With all this interest, many groups have tried different methods to solve these sorts of problems—myself included,” said Fielding. “However, as a community, we've been lacking a way to properly compare all of these efforts because each of us have tried our own methods on our own training sets without a clear way to compare apples to apples.”
The project, Polymathic AI, uses technology similar to that powering large language models such as OpenAI’s ChatGPT or Google’s Gemini, but instead of ingesting text, the project’s models learn using scientific datasets from across astrophysics, biology, acoustics, chemistry, fluid dynamics and more, essentially giving the models cross-disciplinary scientific knowledge. The goal is to create multidisciplinary AI models that will enable new discoveries about our universe.
Fielding provided two of the high resolution, astrophysically relevant training sets to the project, by undertaking what he called a “truly monumental effort” to develop a benchmark for these sorts of fluid dynamics problems. His team compiled a large set of test problems that span a huge range of conditions and sorts of problems researchers would want to try, then presented the data in a uniform, accessible way that enabled scientists to try their different models out.
The Polymathic AI team has just released two of its open-source training dataset collections to the public — a colossal 115 terabytes in total from dozens of sources — for the scientific community to use to train AI models and enable new scientific discoveries. (For comparison, GPT-3 used 45 terabytes of uncompressed, unformatted text for training, which ended up being around 0.5 terabytes after filtering.)
The full datasets are available to download for free from the Flatiron Institute and accessible on HuggingFace, a platform hosting AI models and datasets.
Linda B. Glaser is news and media relations manager for the College of Arts and Sciences.
More News from A&S